
A Complete Guide to Building Scalable, Cost-Optimized Applications on AWS GenAI

Executive Summary
- Building generative AI solutions on AWS requires balancing scalability, cost control, and data governance across every stage of deployment.
- Key success factors include efficient model hosting with Amazon Bedrock, automated scaling through FinOps-driven policies, and continuous monitoring across regions.
- Reliable operations depend on unified observability, retraining loops, and financial accountability.
- NOVA helps you implement these production-ready frameworks to make GenAI systems predictable, efficient, and financially stable.
- Success starts with designing for scale rather than reacting to it.
Book a consultation with NOVA to see how we can help.
***
Building scalable applications on Amazon Web Services sounds simple until costs, latency, and governance start pulling in different directions. But what looks efficient in a test environment rarely holds up once traffic spikes.
You’ve probably seen early GenAI wins stall once pilot code meets production traffic. And that’s where real architecture choices start to matter.
In this article, we'll show you how to structure your AWS Generative AI stack for predictable cost and performance. You’ll compare scaling frameworks, see proven design patterns, and learn how to balance efficiency with financial control.
The AWS GenAI Ecosystem
AWS GenAI is a connected framework inside Amazon Web Services that lets you build, train, and scale intelligent applications using pre-trained foundation models and managed AI technology services. It combines tools like Amazon SageMaker, Bedrock, and native orchestration pipelines to turn experimentation into production-ready automation.
And this year, many IT leaders see generative artificial intelligence as a higher investment priority than even cybersecurity. This is a clear sign of how quickly it’s become core to enterprise strategy.
Also, you can watch this short video to see how generative AI evolved and why it’s such a key part of the AWS ecosystem:
Why Choose AWS for Generative AI Applications?
AWS provides a fully managed platform for building and scaling Generative AI applications.
Services such as Amazon Bedrock offer API-based foundation model access with secure VPC integration, model invocation logging, and Guardrails for responsible AI (AWS Bedrock Developer Guide).
For training and optimization, Amazon SageMaker includes distributed training, managed spot instances, model registry, and MLOps pipelines (AWS SageMaker Technical Overview).
Security controls are enforced through IAM, KMS, CloudTrail, and AWS PrivateLink, aligned with AWS Well-Architected Security best practices.
That means you can move from experiment to production without redesigning your stack. Here’s what makes AWS the strategic choice for GenAI:
- Elastic scalability across on-demand and serverless architectures.
- Enterprise-grade security with IAM, KMS, and encryption by default.
- Cost efficiency through pay-as-you-go services and automated FinOps controls.
- Native prompt engineering and model lifecycle management with Bedrock and SageMaker.
- Deep integration with existing data and DevOps environments.
And, here’s a quick example: NOMMAD built a serverless AI negotiation platform using Amazon Bedrock (Claude model) with our GenAI expertise at NOVA. The project cut negotiation cycles from days to seconds while improving accuracy and cost control. NOVA can help you achieve the same level of scale and predictability.
Schedule a call with NOVA and start building with precision, speed, and control.
How to Scale in AWS GenAI: Best Practices and Frameworks
Scaling GenAI applications on AWS requires clear frameworks. So, you need patterns that balance speed, control, and cost across your pipeline. To help you with that, here are the proven frameworks and practices that allow you to scale GenAI applications efficiently on AWS.
1. Start Serverless with AWS Lambda and API Gateway
Serverless architectures scale instantly while providing predictable downstream control. Lambda concurrency settings, reserved concurrency, and API Gateway throttling protect Bedrock or SageMaker endpoints from traffic storms.
This makes serverless ideal for inference orchestration, model routing, pre-processing, and cost-controlled request shaping.
Every new request scales automatically, and you pay only for what runs. It’s ideal for inference orchestration, model routing, and lightweight pre-processing. These are areas where predictability matters more than raw throughput.
Offloading this layer allows your teams to focus on higher-value optimization work instead of capacity management. And since serverless integrates cleanly with other AWS tools, you maintain observability and governance across your architecture.
Start here if your GenAI workloads are still maturing or if your team needs quick iteration cycles without long provisioning delays.
2. Choose the Right Foundation Model for Your Use Case
Model choice is one of the most direct levers you have over latency and cost. Amazon Bedrock gives you access to models like Titan Text, Claude, and Jurassic. Foundation models on Bedrock, such as Amazon Titan, Anthropic Claude, and Amazon NOVA, offer different advantages depending on workload characteristics.
Instead of assuming one model “usually” performs better, selection should be based on measurable metrics such as latency, cost per token, context length, and accuracy for the target task.
The best approach is to match the model to the user experience you want to deliver. For example, low-latency summarization can run on smaller models, but analytical dialogue might need deeper context.
Pro tip: Recent Amazon NOVA models offer lower latency and cost, up to 75% cheaper than earlier options. This makes them a strong default for scaling production systems.
Also, tie model selection to clear metrics such as response time, cost per token, and quality at scale. In other words, pick the smallest model that still meets your accuracy and performance targets.
3. Use Amazon SageMaker for Training and Optimization
Once your workloads move past basic inference, Amazon SageMaker gives you the control and scale to manage training, tuning, and optimization in one place. It’s built for teams that need to balance performance with governance rather than just push more GPUs into the mix.
The value here is operational consistency.
You can manage distributed training, fine-tuning, and endpoint scaling with usage-based billing and native AWS monitoring. CloudWatch, SageMaker Studio metrics, and Cost Explorer give teams visibility into spend. That means your data scientists stay focused on improving model performance while your platform team maintains control of budgets.
That matters because when retraining cycles get expensive, automation is what keeps a product moving forward instead of stalling. SageMaker supports that scalability with autoscaling, Spot Training, model registries, and monitoring features that enable FinOps practices like granular cost tracking and allocation.
You can use it once your models need repeatable optimization and versioning instead of just quick tests.

4. Implement Observability Across Model Pipelines
Scaling GenAI without observability is like flying blind. You need to see latency, cost, and output quality across every stage of your model pipeline. Tools like Amazon CloudWatch, Datadog, and SageMaker Model Monitor give you that visibility.
Production GenAI systems require visibility across latency (P95/P99), token throughput, failure rate, drift indicators, and cost per request.
CloudWatch, SageMaker Model Monitor, and X-Ray provide actionable metrics on inference performance, model quality, and data consistency.
AWS Prescriptive Guidance also recommends tag-based cost allocation, Anomaly Detection, and automated AWS Budgets alerts as part of a FinOps feedback loop between engineering and finance teams.
So, you can tie observability directly to business outcomes such as SLA adherence, cost per request, or output reliability. This helps leadership see GenAI not as an experimental expense but as a measurable system.
NOVA extends this with FinOps dashboards and governance frameworks that unify technical and financial insight. This way, scaling stays not only stable but also fully explainable.
5. Automate Scaling and Cost Governance with FinOps
Cost efficiency in GenAI is never accidental because it comes from continuous governance. Connecting AWS Budgets, Savings Plans, and NOVA’s FinOps automation allows you to align compute growth with real financial targets. This creates visibility across teams while keeping spending predictable, even as workloads scale.
Why do you need this?
Well, GenAI workloads fluctuate with demand, and without automated controls, costs rise faster than usage. FinOps provides that feedback loop between engineering and finance, which helps you detect drift before it becomes waste.
Research by SMX found that companies limiting cloud waste to 10% could prevent nearly $400K in overspend per $1M baseline. This is proof that governance compounds over time.
NOVA’s framework embeds FinOps directly into your cloud technology pipelines by linking model performance to budget thresholds. You stay Agile without losing financial control. Scaling GenAI responsibly is about building systems that pay for the value they create.
6. Secure Data and Model Access Early
Security in GenAI starts long before deployment. The key is controlling who can access your models, data, and prompts. AWS makes this easier through IAM roles, KMS encryption, and private VPC endpoints. All of which protect traffic between your GenAI services and core systems.
But scaling usually introduces exposure. Every integration point or shared dataset can become a weak link. Establishing clear access boundaries early helps you reduce downstream risk while maintaining compliance standards like SOC 2 and GDPR.
You can use KMS for end-to-end encryption and enforce least privilege through IAM policies. This protects sensitive customer or operational data during training and inference. Pair this with continuous key rotation and audit logging to maintain traceability.
Ready to make your GenAI workloads faster, leaner, and easier to manage on AWS? Talk to NOVA and see how we can help you scale with confidence.
7. Deploy Multi-Region Inference for Low Latency
Latency shapes user experience. Global traffic spikes can slow responses if everything relies on a single location. Multi-region inference helps keep latency low by routing requests closer to users and providing failover resilience if a region becomes unavailable. Amazon SageMaker endpoints and global CDNs can support this pattern.
That said, multi-region deployment isn’t always necessary. Many GenAI systems run well with a single-region endpoint paired with global routing or caching. Multi-region architectures make the most sense for global, latency-sensitive, or compliance-constrained applications where a few hundred milliseconds affect customer satisfaction and system reliability.
If you do choose multi-region, design for replication without waste. Use routing policies, caching, and automation to avoid unnecessary data movement or retraining. Also, connect these decisions to cost governance so scale doesn’t turn into overspend.
8. Monitor User Feedback to Retrain Models Continuously
Performance doesn’t end at deployment, but it evolves with user behavior. Collecting real-world feedback and retraining models continuously allows you to keep quality and accuracy aligned with how your users interact.
For context, drift happens quietly. Model performance degrades not because of failure, but because business operations and data patterns shift. So, integrating user feedback loops into your GenAI services ensures your models adapt rather than decay.
AWS tools like Amazon SageMaker Model Monitor and Bedrock evaluation APIs can track changes in prediction quality and prompt effectiveness. You can combine that with tagging and analytics to link user outcomes directly to retraining triggers.
Real-World Use Cases with AWS GenAI
Scaling frameworks are useful, but the real proof comes from what teams actually build. These are the practical ways AWS GenAI services are being applied to solve measurable business problems and drive value across industries.
Organizations across retail, finance, and telecom are adopting AWS GenAI patterns to improve personalization, reduce fraud investigation time, and automate customer support workflows.
These examples are based on publicly described AWS case studies and partner solutions, illustrating common patterns rather than universal industry behavior
Personalization and Recommendation Engines
Retailers now use Amazon Bedrock with Amazon Titan to create personalized product recommendations that update in real time as users browse.
Pro tip: We advise you to combine behavioral data with prompt-driven personalization, so every interaction feels relevant without extra infrastructure cost. That way, you move from static recommendations to adaptive systems that learn continuously from clicks, purchases, and even timing patterns.
Besides, Titan’s natural language processing capabilities make it easier to generate context-aware outputs that align with a shopper’s intent. That means you strengthen:
- Engagement
- Inventory accuracy
- Campaign precision
- Business intelligence visibility
The result is a recommendation engine that scales with demand and maintains consistent experiences across every channel.
Fraud Detection and Anomaly Analysis
Financial teams use SageMaker and Titan embeddings to model transaction behavior and detect subtle irregularities faster. Instead of relying on static rule engines, they analyze patterns in historical and live data to flag unusual spending or access anomalies.
You need this because fraud detection depends on precision. Too many false positives slow legitimate transactions, while missed signals lead to costly breaches. Embedding-based anomaly detection gives you probabilistic insights instead of binary thresholds, which improves both accuracy and user trust.
Remember: We advise you to integrate this into broader business processes so investigations happen in minutes rather than hours. This includes linking to alerts, dashboards, and automated response systems. It’s a measurable way to strengthen governance while keeping performance stable under variable loads.
Customer Support and Knowledge Automation
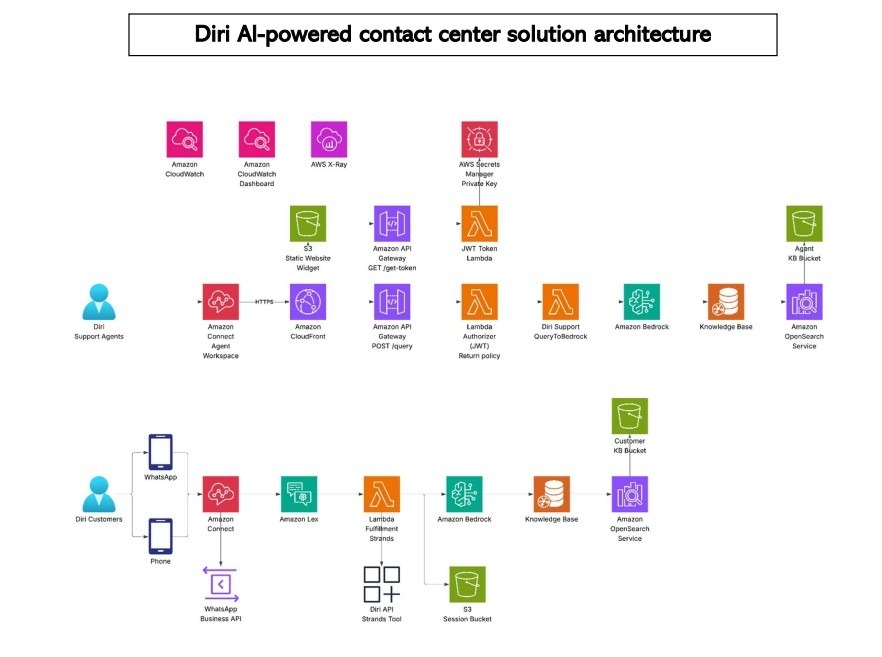
If you’ll read our Diri Telecomunicaciones case study, you’ll learn that we used Cloud used Amazon Bedrock with Amazon Connect and Lex to build an AI-powered contact center assistant. The system leverages retrieval-augmented generation to deliver real-time answers and reduce queue times.
This model adapts dynamically to user context, which allows 24/7, multilingual support without overloading human agents. The result is faster resolution and improved customer experience, supported by secure integrations and scalable backend services.
It’s a strong example of how GenAI can modernize legacy workflows without rebuilding them entirely. With intelligent routing, data protection, and contextual understanding, the Diri solution shows what operational excellence looks like when AI meets cloud-native design.
Predictive Maintenance and Operational Analytics
Manufacturing and logistics teams apply GenAI with IoT telemetry to forecast asset failures before they occur. Here’s what that looks like:
- They use models trained on temperature, vibration, and cycle-time data to predict anomalies.
- These insights drive proactive maintenance scheduling, which reduces downtime and extends equipment life.
- When paired with cloud-based AI/ML systems, retraining happens continuously to ensure predictions evolve with operational patterns.
The broader impact is twofold: cost reduction through fewer outages and higher productivity through smarter resource planning. It’s a tangible way to connect machine data with strategic decision-making, where AI becomes an enabler of business resilience rather than just efficiency.
Challenges and Solutions in Scaling GenAI on AWS
Scaling GenAI services brings major advantages, but it also introduces a new set of operational and financial trade-offs. These challenges appear once you move beyond pilots into production environments that must stay stable, fast, and cost-effective.
Here are the key areas that demand careful planning and proactive design:
- Managing GPU costs and instance availability: Demand for compute grows faster than budgets. You can mitigate this by combining on-demand and spot capacity, using model quantization, or offloading lighter tasks to serverless layers. The point is to stabilize spend while maintaining throughput.
- Balancing latency with accuracy in real-time inference: Model performance usually competes with user experience. Optimizing in-context learning and caching partial results can help you reduce lag without sacrificing precision.
- Preventing model drift with ongoing monitoring and automated retraining: Drift is inevitable as data evolves. Continuous evaluation, feedback loops, and scheduled retraining cycles keep models relevant and dependable over time.
- Governance and data residency requirements for regulated industries: Compliance can’t be an afterthought. You can use regional isolation and clear data lineage controls to align with standards like GDPR or HIPAA while maintaining operational agility.
Accelerate GenAI Adoption with NOVA
Adopting Generative AI at scale requires more than the right technology stack. It takes a strategy that connects architecture, governance, and financial control into one continuous system.
That’s where NOVA helps you move faster with fewer unknowns.
NOVA designs, deploys, and scales AWS GenAI solutions built on Amazon Bedrock and Amazon SageMaker. The focus is on creating frameworks that handle variable workloads, reduce GPU waste, and keep performance consistent across regions. You get a structured roadmap that combines automation, observability, and data integration without rebuilding your existing systems.
Also, FinOps is built into every layer of NOVA’s approach. Automated monitoring ties resource usage directly to budgets, which gives you real-time visibility into training and inference costs. This control lets you scale with confidence instead of reacting to overruns.
NOVA also integrates GenAI capabilities into your existing data lakes and pipelines to create a unified workflow for analytics and production. The result is a faster path from prototype to value without losing financial or operational clarity.
Ready to see how this works in your environment? Book a consultation with NOVA and start scaling GenAI efficiently on AWS.
Comments