
10 Cloud Scaling Strategies Every eCommerce Leader Needs Before Black Friday

Executive Summary
- Black Friday traffic surges expose weaknesses in cloud scalability, response time, and architecture design.
- Reliable cloud infrastructure depends on predictive scaling, automation, and pre-tested capacity thresholds that adapt ahead of demand.
- Effective scaling plans balance performance, observability, and FinOps control to prevent revenue loss during high-volume sales.
- Real-time visibility across compute, storage, and databases reduces latency and avoids failures that disrupt the customer experience.
- Continuous testing, right-sized scaling policies, and post-event reviews turn reactive scaling into a predictable process.
Ready to validate your scaling plan? Schedule a consultation with NOVA’s AWS experts today.
***
Black Friday exposes the limits of every e-commerce platform. Traffic surges hit fast, and even a small delay can drain revenue as shoppers abandon carts. A few seconds of latency can drop your conversion rate by double digits and turn a record sales day into a recovery effort.
The difference between surviving and crashing typically comes down to how well your system scales before the peak starts. NOVA helps you build that readiness with AWS-backed automation, performance tuning, and FinOps control that hold steady under extreme load.
In this article, you’ll see how to prepare, scale, and stay reliable. Let's get started!
What Is Cloud Scaling in eCommerce?
Cloud scaling in eCommerce means expanding or reducing your cloud resources automatically to handle sudden changes in demand. The point is to stay responsive during peak events without slowing transactions or increasing cost waste.
Elasticity matters here because flash sales don’t build up gradually. In many cases, they just strike within minutes. If your capacity lags, checkout queues grow, and shoppers drop off before paying.
Besides, these eCommerce traffic spikes come in short, extreme bursts with high concurrency, especially during checkout. This behavior makes elasticity a direct requirement for stability and performance.
Watch this quick video to see how cloud scalability and elasticity work in action:
Why Black Friday Cloud Scaling Matters More Than Ever
Research from Actindo found that even a one-second delay during a spike can cause an 11% drop in page views, a 7% drop in conversions, and a 16% drop in satisfaction. That means one slow page could cost you millions during peak hours.
Black Friday traffic surges are unpredictable, and downtime directly erodes profit. And many teams still rely on reactive scaling, which usually kicks in too late.
That approach drives wasted cloud spend, uneven load balancing, and irregular performance across regions. Without multi-region redundancy or full observability, small issues turn into full-scale incidents that affect both customers and finance.
The real opportunity lies in combining automation, observability, and right-sized architecture.
When you align performance metrics with predictive scaling and FinOps governance, your system scales seamlessly. This protects uptime, cost, and user experience before the rush begins.
Scaling in Cloud Computing: 10-Step Plan
Scaling in cloud computing means preparing your systems to handle sudden spikes without breaking performance or budget. Each step helps you connect scalability decisions with uptime, cost, and performance.
Here are the ten strategies that keep your systems steady under peak load.
1. Use Predictive Auto-Scaling
Predictive auto scaling gives you time to act before demand surges. You’ll basically analyze historical traffic data to forecast workload patterns and scale EC2, ECS, or Lambda resources ahead of the peak. That way, you prevent service lag during checkout spikes and keep application performance consistent across every transaction.
In practice, predictive scaling has shown high accuracy in forecasting resource needs and consistently outperforms reactive methods. The key is to train scaling models on real production data (not just lab tests), so they reflect your actual load behavior.
When done right, predictive scaling:
- Smooths capacity jumps
- Minimizes over-provisioning
- Reduces manual intervention during Black Friday chaos
The result is a responsive system that meets demand the moment it arrives. Use it to maintain uptime and a frictionless payment processing experience even under extreme pressure.
2. Horizontal vs. Vertical Scaling: Finding the Right Mix
Horizontal scaling gives you more flexibility by adding multiple instances to share the workload. It supports fault isolation and improves resilience because traffic is distributed across nodes. When one instance fails, the rest keep the service alive.
Vertical scaling, on the other hand, boosts resources like CPU or memory within a single instance. It’s simpler to manage but reaches limits faster, especially under sustained traffic.
The most effective strategy uses both. You can:
- Distribute front-end and API workloads horizontally for throughput.
- Scale databases or legacy systems vertically when they hit performance ceilings.
This hybrid model helps you handle variable traffic while keeping costs predictable.
For many teams, the ideal balance is dynamic. You can use horizontal elasticity during peak website scaling, then controlled vertical upgrades for bottlenecked components once the rush ends. That’s how you maintain stability without overpaying for idle resources.
3. Implement Load Balancing for Traffic Distribution During Peak Hours
During peak load, even the strongest systems struggle without proper load balancing. A well-configured load balancer splits traffic evenly across multiple instances and prevents single points of failure.
With Amazon Web Services, you can use:
- Application Load Balancers for HTTP and HTTPS traffic
- Network Load Balancers for lower-latency connections
- Features like sticky sessions to keep returning shoppers tied to the same node
- Connection draining so ongoing transactions can finish before an instance shuts down
Another thing to mention is that SSL termination offloads encryption from backend servers, which improves speed during heavy traffic. But the hardest part is maintaining session consistency across multiple nodes. That’s where distributed caching and token-based session management help.
Together, these techniques keep cart data stable, reduce cart abandonment, and maintain smooth checkout flows. When configured correctly, your quality of service remains high even when traffic surges far beyond forecasted peaks.
4. Adopt Multi-Region and Multi-AZ Deployment
Deploying across multiple regions and availability zones protects your storefront from downtime and regional outages. A Multi-AZ setup duplicates workloads within a single region for fault tolerance, while a multi-region strategy extends that protection globally.
If you use AWS, you can automate failover between regions with Route 53 health checks to shift traffic as soon as an outage is detected. This way, your customers will experience consistent performance no matter where they shop.
But the tradeoff is cost and governance complexity. So it’s important to define policies around replication frequency, data residency, and access control.
Many teams choose a hybrid cloud approach where they combine on-premises data with distributed AWS regions to balance compliance and availability. This configuration (when done right) minimizes latency, strengthens data protection, and guarantees business continuity even when part of your infrastructure fails under pressure.
Ready to test your scalability ahead of Black Friday? Our cloud engineering services can help you run your architecture through a load-ready assessment.
5. Run Load and Stress Testing Ahead of Black Friday
Load and stress testing let you find weak points before your customers do. Tools like AWS Fault Injection Simulator and JMeter help you replicate real peak traffic, validate auto scaling policies, and measure how your system behaves under extreme pressure.
So, you should focus on three thresholds to gauge your readiness. That includes latency, error rate, and throughput. But the thing is, teams usually overlook hidden limits, like API rate throttling or database locks, which can quietly stall transactions.
So, to get meaningful results:
- Test full workflows rather than isolated endpoints.
- Mirror real session duration and checkout activity.
- Include your third-party APIs since they can slow performance without clear visibility.
- Use your results to tune scaling triggers, right-size infrastructure, and remove blind spots.
When Black Friday hits, you’ll already know how your system reacts and how to keep performance stable when load spikes suddenly.
6. Scale Databases for Read and Write Bursts
Database performance can make or break your scaling plan. Services like Aurora Serverless and DynamoDB auto-scaling handle fluctuating read and write loads without manual tuning. During flash events, that flexibility keeps transactions flowing instead of queuing.
So:
- Add caching layers such as Redis or ElastiCache to reduce query pressure on your main database, and configure read replicas to offload analytics queries.
- Connection pooling also helps by preventing idle connections from draining resources.
- While there, keep an eye on IOPS, query latency, and index databases regularly to spot performance drift early.
- For more demanding workloads, database sharding can distribute tables across multiple nodes and improve throughput and fault isolation.
Remember: Well-designed scaling prevents slow queries and timeouts that frustrate shoppers and impact order management.
When your data layer scales as efficiently as your app, your site stays fast even under the heaviest buying pressure.
7. Automate Scaling Policies with Infrastructure as Code
Automation turns scaling from a manual reaction into a controlled process. When using Terraform or AWS CloudFormation:
- You can define scaling thresholds, triggers, and rollback logic as code. This creates a version-controlled, auditable framework that makes every scaling decision repeatable and consistent.
- You reduce the risk of human error when demand spikes. You can script precise parameters to trigger automatic adjustments across EC2, ECS, or Lambda. This includes CPU utilization, queue depth, or transaction volume.
The key is to connect these triggers to both performance testing data and FinOps insights, so scaling aligns with actual business needs rather than theoretical targets. Once policies are in place, you can test them safely in staging before production rollout.
With this approach, scaling becomes part of your release cycle instead of a last-minute patch. That’s how you keep speed, stability, and cost in sync during Black Friday surges.
8. Integrate Observability and Real-Time Monitoring
Observability gives you control when systems start to strain:
- Tools like Datadog and CloudWatch track scaling health, latency, and anomalies as they happen.
- Using real-time monitoring tools and custom alerting mechanisms allows you to detect bottlenecks before they escalate into outages.
- Dashboards showing error rates, transaction latency, and scaling events help teams respond in minutes instead of hours.
Now, here’s where NOVA makes a difference.
NOVA integrates Datadog and AWS telemetry into a single monitoring layer. This can help you visualize how scaling policies affect cost, uptime, and throughput in real time.
With unified visibility, you can connect performance to actual incident management outcomes rather than just system metrics. When thresholds are breached, automated alerts trigger rapid recovery actions or escalation workflows.
That level of control keeps your infrastructure as a service responsive and resilient during unpredictable Black Friday load patterns.
9. Apply FinOps Practices to Control Scaling Costs
FinOps helps you scale with financial accountability. The goal is to maintain elasticity without losing track of cost impact. So, you can start by combining AWS Savings Plans with Spot Instances to balance stability and flexibility. Savings Plans handle predictable workloads, while Spot Instances absorb short-term spikes at a fraction of the cost.
But what really matters is automation and governance. So, you need to:
- Define clear budgets.
- Set utilization targets.
- Use automated policies to reclaim idle capacity before it turns into waste.
- Integrate cost visibility into your real-time data processing dashboards so engineers can see spend alongside performance metrics.
NOVA takes this a step further by combining automation with expert oversight. This gives you a predictable ROI even in volatile periods. We take a FinOps-first approach, so as you scale, you can stay on track with both uptime goals and financial performance.
That way, you can scale confidently without overspending during Black Friday or other mainstream events like Cyber Monday.
10. Conduct Post-Event Review and Continuous Optimization
Once traffic stabilizes, the real improvement work begins. We advise you to review your scaling performance to learn from actual demand. We advise you to:
- Analyze your scaling logs, query processing data, and infrastructure telemetry to spot underused or overprovisioned resources.
- Identify where scaling triggered too late, too early, or beyond the needed threshold.
- Look for patterns in failed requests, servers not responding, or bottlenecks in application layers.
- Then, refine your auto scaling policies to improve timing and precision for future peaks.
Continuous tuning ensures that scaling efficiency grows over time instead of resetting with every event. Post-event reviews also uncover how operational processes held up under pressure. This includes whether alerting worked, incident handoffs were smooth, or rollback plans were tested effectively.
Treat this as an ongoing cycle instead of a postmortem. Each iteration strengthens your readiness for the next surge and gives you tighter control over reliability, cost, and recovery speed.
Pro tip: Want to see how leading retailers are partnering with experts to scale faster and smarter? Read this quick guide on the top cloud consulting partners reshaping eCommerce growth in 2025.
Cloud Scaling Strategies Examples
Real-world scaling outcomes usually show what theoretical diagrams can’t: how design choices translate to uptime, cost, and customer experience. Check out the examples below to see how NOVA helps companies like yours modernize architectures to handle peak loads.
Brightfield: Microservices and Zero-Downtime Deployments
Brightfield struggled with monolithic releases that triggered downtime during updates. So, we migrated the system to a containerized microservice setup on AWS, using a managed services layer to handle operations. Each service now scales independently, and that has improved agility and fault isolation.
Deployments happen without disruption and keep checkout sessions uninterrupted. The shift also replaced legacy Oracle licenses with pay-as-you-go storage, which helped the company save over $500k annually.
With faster go-to-market cycles and stronger fault tolerance, Brightfield turned its infrastructure into a flexible, cost-efficient platform ready for seasonal surges.
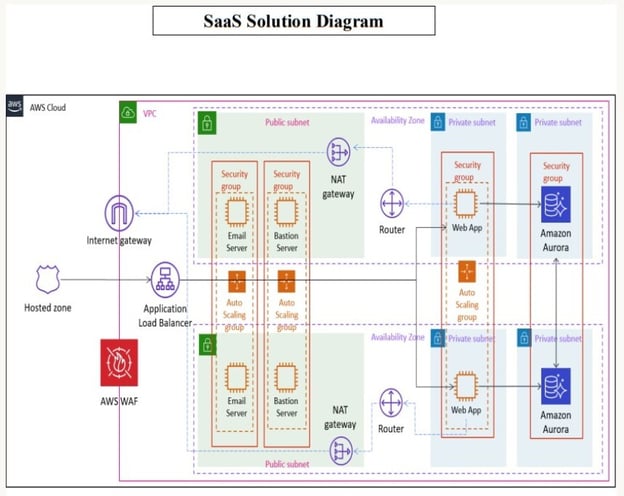
Cosoft: Automated SaaS Platform for Event Management
Cosoft’s single-server architecture limited scalability and automation. So, NOVA restructured it using AWS CloudFormation and CI/CD pipelines to turn infrastructure provisioning into a fully automated process. Each event now runs in an isolated, horizontally scalable environment that launches within minutes.
Aurora databases deliver up to five times the performance of MySQL and support 20,000 concurrent requests with consistent response times. Also, removing licensing dependencies and human intervention reduced operating costs while improving reliability.
The result is a SaaS platform that scales as easily as an eCommerce system during major traffic spikes.
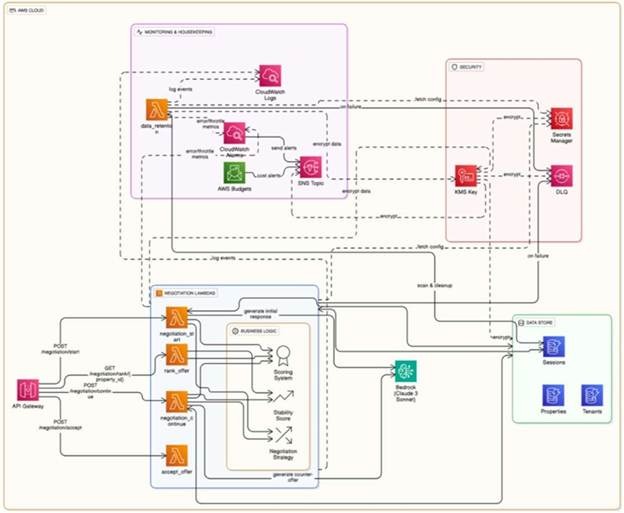
Nommad: Serverless Architecture with Low Latency and Cost Control
Nommad’s rental negotiation app runs on a cloud-native model using AWS Lambda and DynamoDB. The setup scales functions automatically and charges only for actual use. As a result, DynamoDB’s millisecond latency and multi-region replication ensure fast responses worldwide.
To keep deployments consistent, AWS SAM templates maintain deployment consistency, while cost tools like Budgets and Cost Explorer provide visibility into usage trends. And when workloads spike, resilient features such as dead-letter queues prevent dropped requests by delivering dependable uptime and strong cost control.
Finix: Faster Transaction Processing and Reliability Improvements
Finix, a payments startup, faced high transaction failure rates and unstable throughput. To address this, NOVA implemented AWS Organizations and Control Tower to centralize access and strengthen governance. Within weeks, transaction errors dropped below 1%, and processing time fell under one second.
These results improved merchant confidence and reliability metrics. Enforcing strict identity and access policies allowed Finix to gain both speed and resilience. This is proof that strong governance architecture directly supports high-performance digital payments.
Partner with NOVA for Scalable eCommerce Reliability
When your revenue depends on uptime, you need a cloud architecture that adapts faster than demand changes. NOVA designs and manages AWS infrastructures built to perform under the toughest retail loads, especially during Black Friday-scale events. The focus is simple: proactive scaling, real-time visibility, and measurable cost control.
Through real-time observability and automated scaling frameworks, NOVA helps you maintain performance without overprovisioning. Each environment is built for agility, supported by FinOps-driven optimization that keeps every scaling decision aligned with budget and ROI. This leads to predictable costs, faster recovery, and confidence during high-stakes sales periods.
For example, NOVA designed a fully cloud-native platform for Antiestatica’s electrostatic laundry monitoring system. Today, the AWS-based architecture runs serverless functions with millisecond latency and scales globally while reducing the total cost of ownership.
When your next traffic surge arrives, don’t leave reliability to chance. Schedule a consultation with NOVA to validate your scaling strategy before peak demand hits.
FAQ
What are the different types of cloud scaling?
The main types of cloud scaling are vertical, horizontal, and diagonal. Vertical scaling adds more power to existing servers, and horizontal scaling adds more servers to distribute load. Meanwhile, diagonal scaling combines both to handle unpredictable demand without service interruption.
What are cloud scalability best practices?
Scalability best practices include using modular architectures, automated scaling policies, and load balancing to spread demand across resources. It also helps to decouple services, use caching, and test scaling thresholds regularly to ensure performance holds during peak loads.
What is the best cloud platform for scaling workloads?
AWS remains the top choice for scaling eCommerce workloads due to its elasticity, auto-scaling, and serverless options that adapt in real time. NOVA adds further value through certified AWS expertise and integrated FinOps practices that align cost with performance outcomes.
What are the top cloud databases for easy scaling?
Amazon Aurora, DynamoDB, and RDS are leading options for handling high-traffic and high-concurrency use cases. Each offers automated scaling, replication, and resilience that keep query performance steady under heavy transactional loads.
Comments